Data Structure: Tree
Intro
In computer science, a data structure is a data organization, management, and storage format that enables efficient access and modification. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data
Basic Info
Tree in computer science is the same as the tree in the real world. But we are more used to put the root on the top to think about the tree.
A tree without any stable point is unrooted tree, it has those equalievent definition:
- Has n points, n-1 edges linked undirected graph
- Undirected graph but without cycle
- Undirected graph which two points have and only have a simple path
In the base as the unrooted graph, the specific point is root.
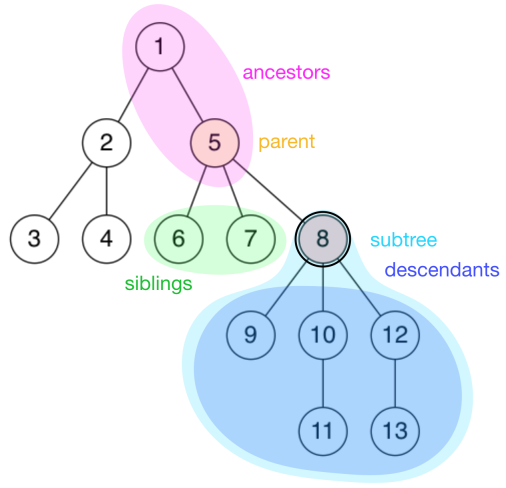
Restore it!
Segment tree
In computer science, a segment tree, also known as a statistic tree, is a tree data structure used for storing information about intervals, or segments. It allows querying which of the stored segments contain a given point. It is, in principle, a static structure; that is, it’s a structure that cannot be modified once it’s built. A similar data structure is the interval tree. A segment tree for a set I of n intervals uses O(n log n) storage and can be built in O(n log n) time. Segment trees support searching for all the intervals that contain a query point in O(log n + k), kbeing the number of retrieved intervals or segments.
So it has every characteristic binary tree has:
There are at most 2^(i-1)^(i$>=$1) points in the number i layer of the binary tree
There are at most 2^(i-1)^(i$>=$1) points in the binary tree which’s depth is i
A binary tree which has n points has log2^n^+1 depth
For a perfect binary tree which has n points, for any point i(1<=i<=n):
If i==1, then i is the root of the binary tree, else if i>1, then i’s parent is i/2
if 2i>n, then i has no left child
If 2i+1>n, then i has no right child
Charastics of Segment tree
almost perfect binary tree.
i’s father is i/2(suppose i is a point in the tree)
i’s brothers are b=i/2*2andanother one is b+1.
i’s children are l=i*2and r=l+1
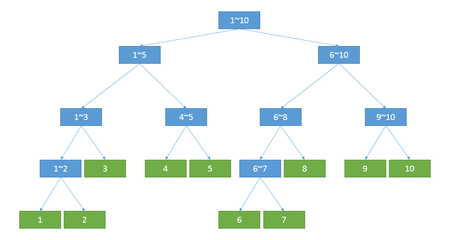
Restoring
Base on the charastic of the binary tree. We can easily build the Segment tree.
Because the segment tree, every point has larger value which is stored in one of its children. So we need to store its children in order to know the segment. And also the value of the point of course. Because the question would ask the data in the original order, so we also need to store those info.
1 | const int mx=100001; |
Building
We build the tree from its root, then its sons. Then we keep build sons’s sons through recursion. And when we finally get to the deepest point of the tree(leaves). We need to memerozie the number for the leaves and restore the value.
1 | void build(int i, int l, int r){ |
Query segment
Query will return the max value for the segment. So it will firtst find out if the request segment is in the domain, and return the value.
1 | long long query(int i,int l,int r){ |
Update value(One point)
Once we changed a point. It will influence its father and all the way to the root.
1 | tr[real[a]].val=k;//IN the main func, change the value of a point |
Update Value(Segment)
When we trying to update the value for a segment, it is impossible to update one point by one pointO(nlogn). So we add a lazy tag which store the value that need to be updated. So the segment update will be more like query segment. So we need to discuss If the segment we need to update is inside the segment…….
1 | void build(int i,int l,int r) { |
Now we know the way to update the value for a segment.
How about the segment’s value time something?(Discussion question)
Binary Indexed Tree
A data structure that can efficiently update elements and calculate prefix sums in a table of numbers.
We can understand it through segment tree. The Binary indexed tree aims to calculate the sum from as
as+1…..at. We can calculate it with segment tree. But what if we want to get it fast? If we can calculate the sum(1t)-the sum(1s-1), it works the same. Then we discover that the right son is no longer needed. We can get them from the father - left son.

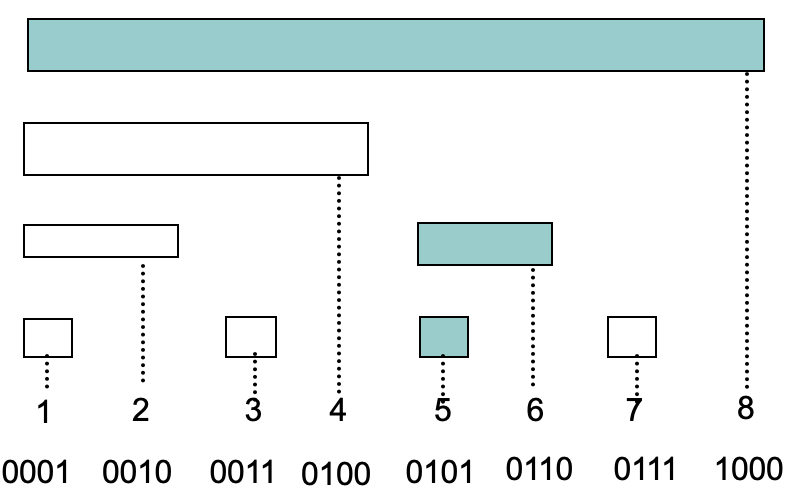
So base on the graph below.
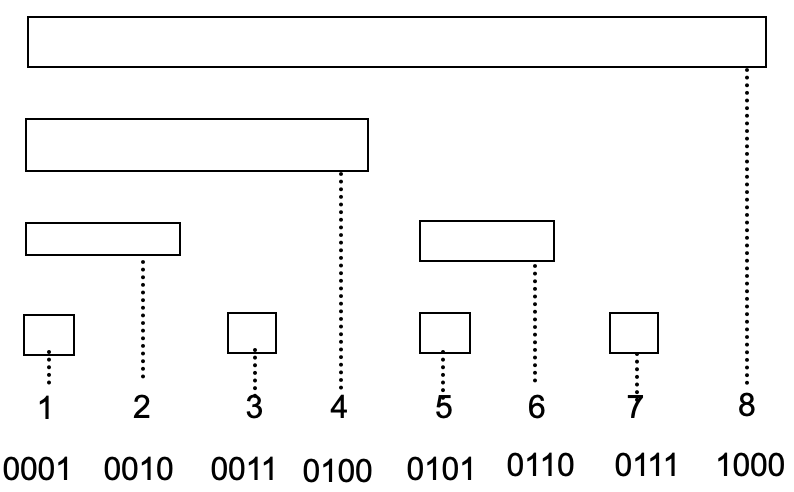
Everytime we minus the last 1 in the binary expression, and add i’s value into the result, we can get the sum easily. This is the importance of lowbit.
| i | Binary Expression |
|---|---|
| 5 | 0101 |
| 4 | 0100 |
| 0 | 0000 |
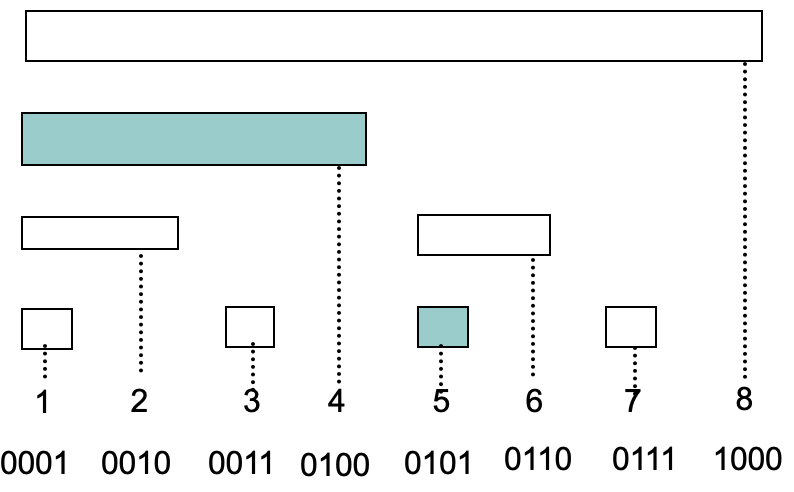
When we update the data, we just add 0001 to the binary expression.
| i | Binary Expression |
|---|---|
| 5 | 0101 |
| 6 | 0110 |
| 8 | 1000 |
Preparation: lowbit()
Lowbit(i) will return the place for 1 in the binary system.
For instance, lowbit(10)will return 2 because (10)2=1010. And 1 is in the place 2.
1 | int lowbit(int x){ |
Realization
1 | int bit[mx+1], n; |
Binary Indexed tree & Inversion
Inversion
For a sequence A. If i<j and A[i]>A[j]. We call A[i] and A[j] are inversion.
So we can find the number of the inversion in this way
1 | int cnt = 0; |
Example
Description
Every year, Farmer John’s N (1 <= N <= 20,000) cows attend “MooFest”,a social gathering of cows from around the world. MooFest involves a variety of events including haybale stacking, fence jumping, pin the tail on the farmer, and of course, mooing. When the cows all stand in line for a particular event, they moo so loudly that the roar is practically deafening. After participating in this event year after year, some of the cows have in fact lost a bit of their hearing.
Each cow i has an associated “hearing” threshold v(i) (in the range 1..20,000). If a cow moos to cow i, she must use a volume of at least v(i) times the distance between the two cows in order to be heard by cow i. If two cows i and j wish to converse, they must speak at a volume level equal to the distance between them times max(v(i),v(j)).
Suppose each of the N cows is standing in a straight line (each cow at some unique x coordinate in the range 1..20,000), and every pair of cows is carrying on a conversation using the smallest possible volume.
Compute the sum of all the volumes produced by all N(N-1)/2 pairs of mooing cows.
Input
* Line 1: A single integer, N
* Lines 2..N+1: Two integers: the volume threshold and x coordinate for a cow. Line 2 represents the first cow; line 3 represents the second cow; and so on. No two cows will stand at the same location.
Output
* Line 1: A single line with a single integer that is the sum of all the volumes of the conversing cows.
Sample Input
1 | 4 |
Sample Output
1 | 57 |
Solution
Of course stimulation can be a good way, easy to think. But use the binary indexed tree can help to save a lot of time. So we sort cows first because when data is sorted from the smallest to the largest, we don’t need to worry about computation. So we need to use struct to restore the value. But we can’t make sure the x value for a cow, we must come up with a way to calculate the cows ( who are before cow i and x<xi)’s sum of x’s absolute value.
So we need to use two Binary Indexed tree to restore the data:
- The number of cows which are before i and x are smaller than xi
- The cows which are before i and x are smaller than xi, the sum of their x value
1 |
|
Lowest Common Ancestor
the lowest common ancestor (LCA) of two nodes v and w in a tree or directed acyclic graph (DAG) T is the lowest (i.e. deepest) node that has both v and w as descendants, where we define each node to be a descendant of itself (so if v has a direct connection from w, w is the lowest common ancestor).
Characteristics
- LCA(u)=u
- LCA(u,v)=u, if and only if u is the ancestor of v
- If u and v are not ancestor of each other, then they are separate in their lca’s son trees
- LCA(A$\bigcup$B)=LCA(LCA(A),LCA(B))
- u and v’s lea must be in the route from u to v(Shortest)
Realization
Easier way
Build a loop, and in the loop fInd the point which is deeper, and jump it to its father. When two points meet together, the poistion is their LCA.
Faster way
We premake a fa[x][i] array, and fa[x][i] Means the 2^i^ ancestor for point x. We can make fa[][]array through dfs.
1 | int lca(int x,int y) { |
The centroid of the tree
Defination
For a point in the tree, calculate its biggest son’s point number. For the point which has the smallest number. That should be the centroid.
Characteristics
- When the root is the centroid, every son’s scale won’t be larger than half of the whole tree
- When calculate the distance from every point to a single point, the centroid will be the smallest
- Conecting two trees through an edge, then the new centroid will be on the route that conect two centroids.
Realization
1 | void getCentroid(int u, int fa) { |
So you might wonder how can we get size and father those kinds of information, and here is the most important method we are going to learn……
The alograthim I am going to talk about actually has no translation. So I just go with my Chinese……
接下来的内容没有英语翻译,所以我要开始说人话了
树链剖分
Concept
“树链” ,就是树上的路径。
“剖分”,就是把路径分类为重链和轻链。
常见的操作方式就是轻重剖分,这种方法能实现任意一点到根结点上的链的个数不超过logn条。
Method
记siz[v]表示以v为根的子树的节点数,dep[v]表示v的深度(根深度为1),top[v]表示v所在的链的顶端节点,fa[v]表示v的父亲,son[v]表示与v在同一重链上的v的儿子节点(姑且称为重儿子)。 下图中圆圈内的数字表示树结点编号;加粗的边代表重链,反之则为轻链;树结点中带有小圆点的表示该条链所在链的顶端结点;
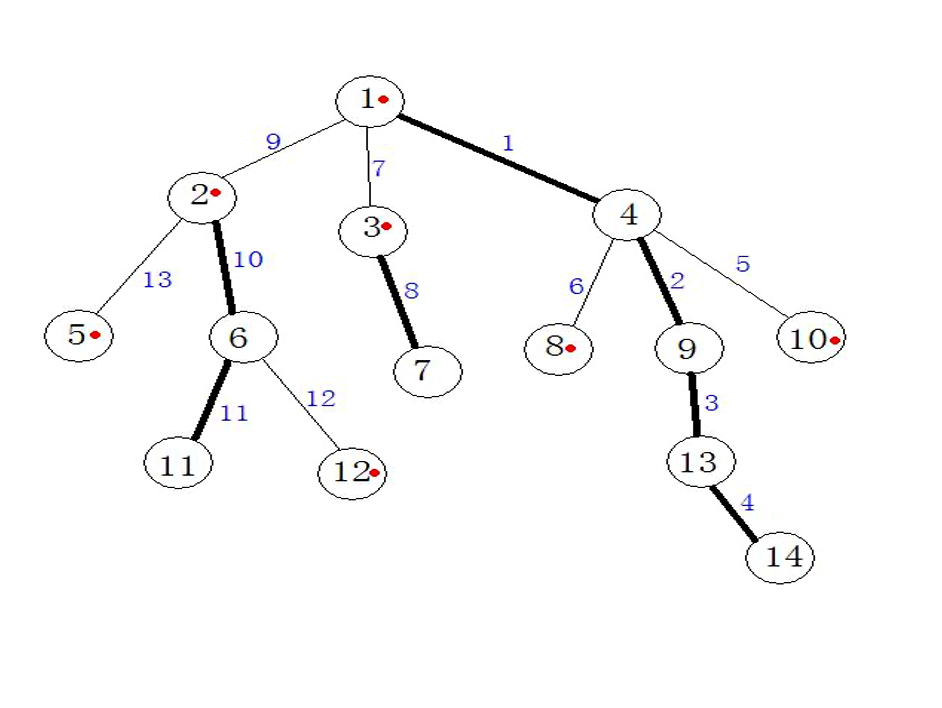
叫法
重儿子:siz[u]为v的子节点中siz值最大的,那么u就是v的重儿子。
轻儿子:v的其它子节点。
重边:点v与其重儿子的连边。
轻边:点v与其轻儿子的连边。
重链:由重边连成的路径。
轻链:轻边。
Charastics
如果(v,u)为轻边,则siz[u] * 2 < siz[v]
从根到某一点的路径上轻链、重链的个数都不大于logn
Realization
用两个dfs(可用bfs)来求出fa、dep、siz、son、top等信息;
dfs_1:
把 fa、dep、siz、son求出来,比较简单,略过
dfs_2:
⒈(重链)对于v,当son[v]存在(即v不是叶子节点)时,显然有top[son[v]] = topv。继续 dfs_2(son[v]);
⒉(轻链)对于v的各个轻儿子u,显然有top[u] = u,进行dfs_2(u)过程。
这就求出了top。
这样就完成了轻重链划分,即树链剖分
1 | void dfs1(int u){// siz、 son、 dep、fa |
Seems to be long, but when we slow down and coding it few more times, it would be easy for us to learn.
例题
P3038 [USACO11DEC]Grass Planting G
题目描述
Farmer John has N barren pastures (2 <= N <= 100,000) connected by N-1 bidirectional roads, such that there is exactly one path between any two pastures. Bessie, a cow who loves her grazing time, often complains about how there is no grass on the roads between pastures. Farmer John loves Bessie very much, and today he is finally going to plant grass on the roads. He will do so using a procedure consisting of M steps (1 <= M <= 100,000).
At each step one of two things will happen:
- FJ will choose two pastures, and plant a patch of grass along each road in between the two pastures, or,
- Bessie will ask about how many patches of grass on a particular road, and Farmer John must answer her question.
Farmer John is a very poor counter – help him answer Bessie’s questions!
给出一棵n个节点的树,有m个操作,操作为将一条路径上的边权加一或询问某条边的权值。
输入格式
* Line 1: Two space-separated integers N and M
* Lines 2..N: Two space-separated integers describing the endpoints of a road.
* Lines N+1..N+M: Line i+1 describes step i. The first character of the line is either P or Q, which describes whether or not FJ is planting grass or simply querying. This is followed by two space-separated integers A_i and B_i (1 <= A_i, B_i <= N) which describe FJ’s action or query.
输出格式
* Lines 1..???: Each line has the answer to a query, appearing in the same order as the queries appear in the input.
输入输出样例
输入 #1
1 | 4 6 |
输出 #1
1 | 2 |
Solution
1 |
|

