Python爬虫
title: 爬取进击的巨人漫画
date: 2020-02-23 15:13:57
lang: zh-Hans
tags:
- Python
categories: 技术
[[0Python3 网络爬虫学习]]
[[1爬虫简介]]
[[2爬虫原理]]
[[3爬虫编程基础]]
[[5Ajax内容爬取]]
[[6异步爬虫和模拟登录]]
[[7javascript逆向简介]]
[[8javascript逆向实战]]
[[信息安全:网页运作原理]]
使用Scrapy爬取进击的巨人漫画
一、简介
自己看到网上有两个大牛分别爬取了合法(Naruto)与非法(你懂的)的漫画,十分感叹,便也想借鉴借鉴,结果大牛的的代码在博主的电脑上运行不了(丧尽天良),所以就只有自己写了一个算是结合版的代码,爬取了这个网站。在此分享给大家,授人以both🐟。
代码已经挂在GitHub上面了,想下漫画的可以滑到最下面观看下载方法,这个方法不仅可以下载进击的巨人,整个网站的漫画都可以爬,建议大家别乱改我设置的延迟,爬的太快了可能会被网站锁IP。
二、环境准备
博主的环境如下:
1 | |
在这里我默认大家都已经安装好了scrapy,传送门
不知道大家会遇到什么麻烦,博主只用了这一句代码:
1 | |
三、基础准备
Scrapy简介(大牛的文章)
Scrapy Engine(Scrapy核心) 负责数据流在各个组件之间的流。Spiders(爬虫)发出Requests请求,经由Scrapy Engine(Scrapy核心) 交给Scheduler(调度器),Downloader(下载器)Scheduler(调度器) 获得Requests请求,然后根据Requests请求,从网络下载数据。Downloader(下载器)的Responses响应再传递给Spiders进行分析。根据需求提取出Items,交给Item Pipeline进行下载。Spiders和Item Pipeline是需要用户根据响应的需求进行编写的。除此之外,还有两个中间件,Downloaders Mddlewares和Spider Middlewares,这两个中间件为用户提供方面,通过插入自定义代码扩展Scrapy的功能,例如去重等。
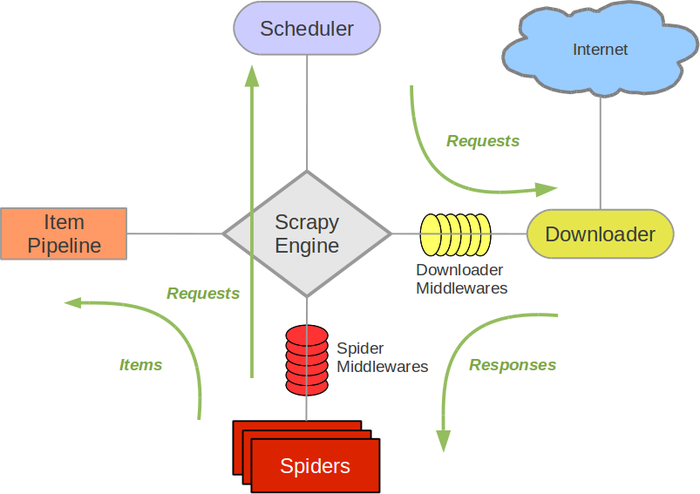
基本思路
注意!这篇文章并不是official文章,一切还以官方教程为准。这里只讲本次操作用到的知识。
- 创建一个Scrapy项目;
- 定义提取的Item;
- 编写爬取网站的 spider 并提取 Item;
- 利用python自带的request库莱下载漫画
四、第二次准备
创建项目
1 | |
然后我们可以观察项目内涉及的文件
1 | |
大部分都没啥用,重点是我们要在spider里面添加一个自己编写的python文件,可以是任意名字,像我就叫他巨人蜘蛛
1 | |
创建spider类
创建一个用来实现具体爬取功能的类,我们所有的处理实现都会在这个类中进行,它必须为 scrapy.Spider 的子类。
在 Titan/spiders 文件路径下创建 titan_spider.py 文件。在里面就开始我们蜘蛛(只猪)的初始化
1 | |
shell分析
在command line里面输入
1 | |
然后你会得到这一堆东西(别🐦它)
1 | |
然后我们就要使用xpath或者是css去寻找指定的页面内容(奥利给干它)
博主也学习了一些时间,建议各位去康康这个教程(求作者给广告费恰饭)
理清思路,现在我们要找到各话的url,通过观察发现这些url都在标签下
观察方法:鼠标右键然后点击inspect,再点一下左上角的选择器就可以查看页面元素的所在位置了
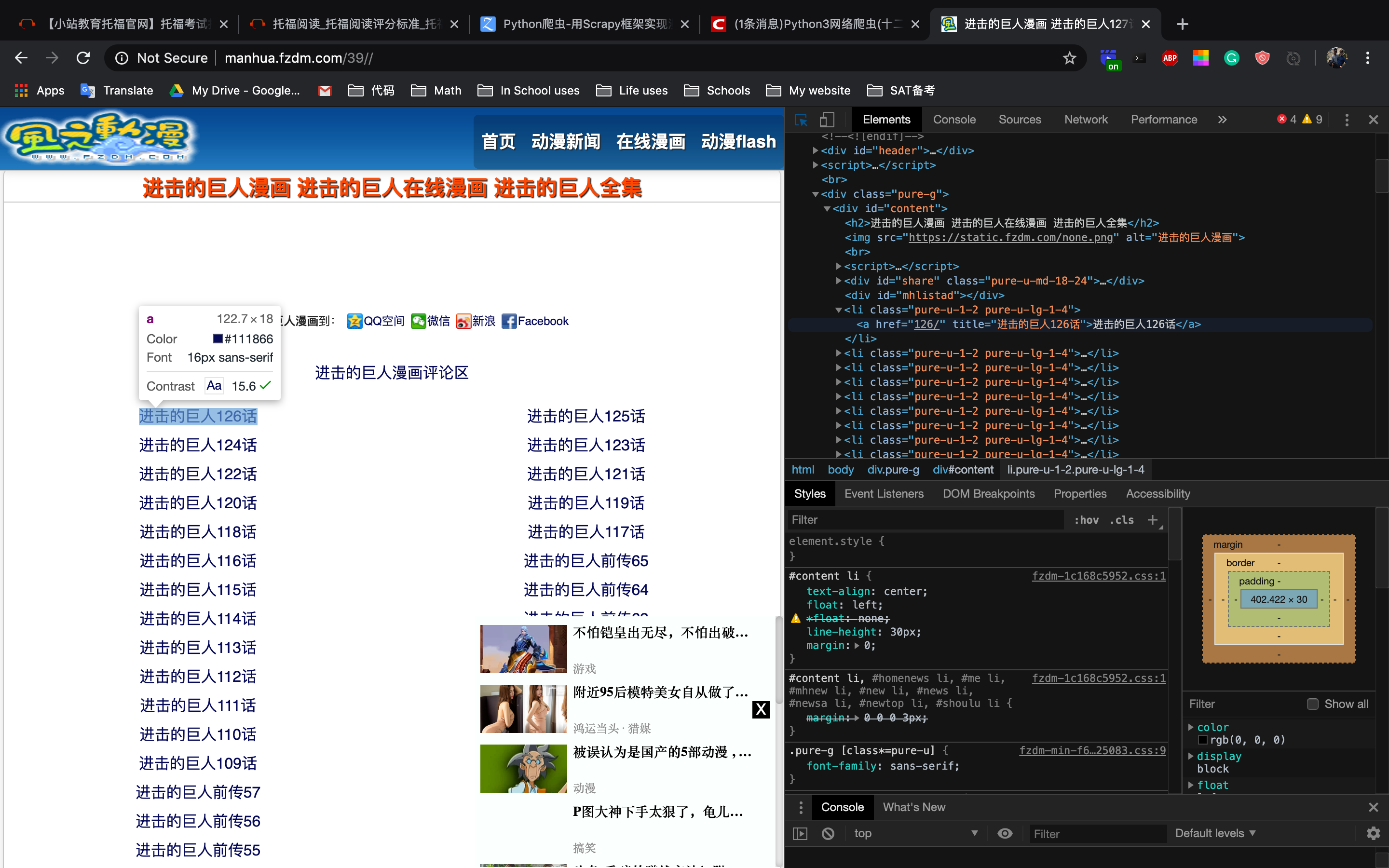
于是输入
1 | |
获取到所有符合这种特征的herf
1 | |
我们发现又有几个浑水摸鱼的url混了进来,不过咱们先把这个放在一边,等会在python里面用字符串操作把它们给筛掉(博主不会一步找到正确url的方法qaq),如果有更好的方法请大神指出(带我带我!)
使用ctrl+d退出之前的shell,分析章节页面。这次我们需要找到图片的url以及下一页的url
再次分析
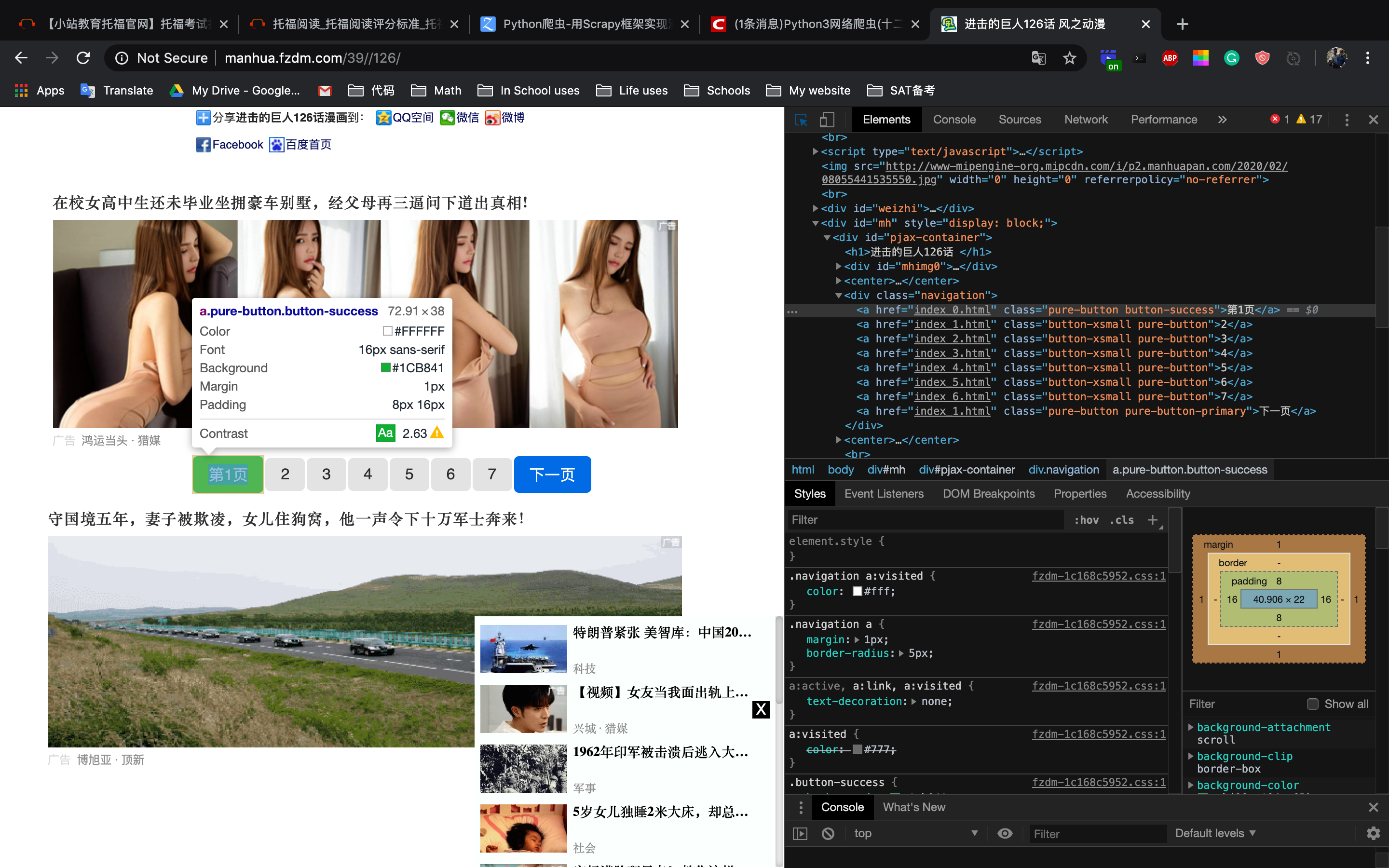
手动@风车动漫的广告商到我这里来把广告费结一下,【手动狗头】
这次我们找一下下一页的url(这个网站他图片的url放的比较日怪)
在command line里面输入
1 | |
然后我们需要再次找到
1 | |
然后老套路
1 | |
我们知道最后一个url就是咱们的next page了
但是!!!
我们这么才能知道这一章什么时候结束呢?
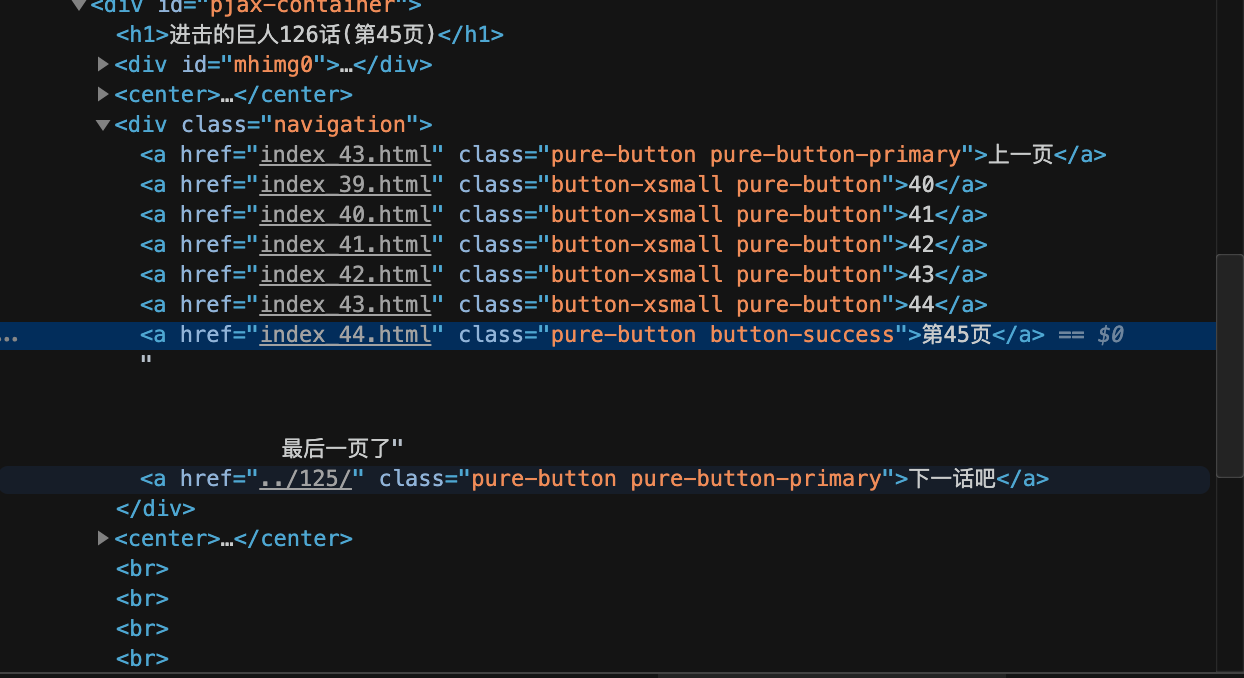
这是我们的最后一页的代码,看起来从url上一点头绪都没有,但是从旁边的文字上我们又有了新的线索,一般它会给出如:下一页这样的信息,最后一页则没有这样的信息,只要我们知道是否有“下一页”,我们就能知道是否为最后一页

所以要获取上面的文字,使用如下方法:
请看第一页与最后一页的对比
1 | |
1 | |
然后既然我们已经知道了判断下一页的方法,接下来就是获取图片链接了
获取图片链接
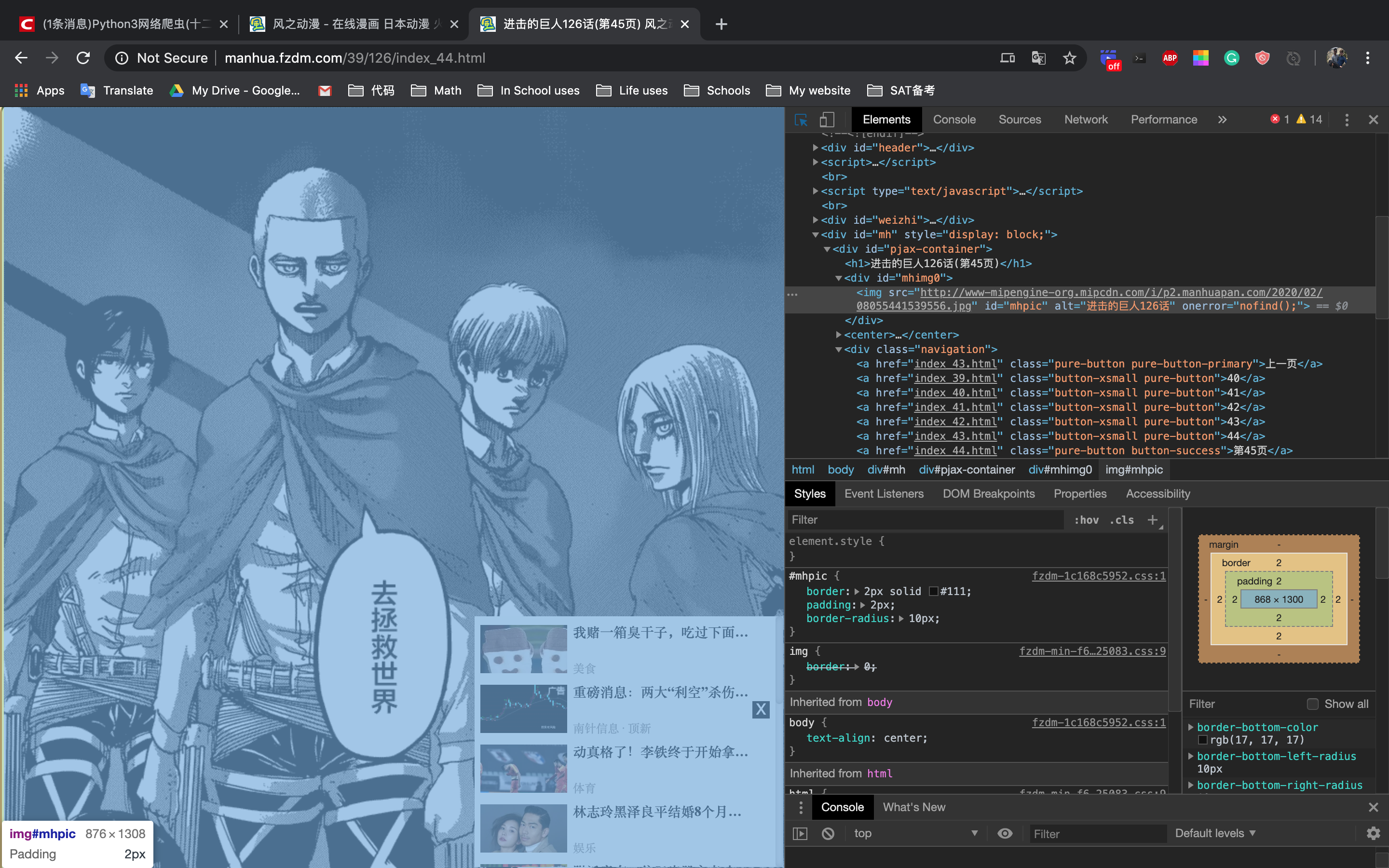
再次选择我们找到了图片的url
但是。。。
1 | |
woc居然找不到图片的url???

于是康康这个蜘蛛获取到的整个html代码
1 | |
我们复制之后打开任意代码编译器然后Command+f寻找这个“2020/02/08055441539556.jpg”url在哪里。
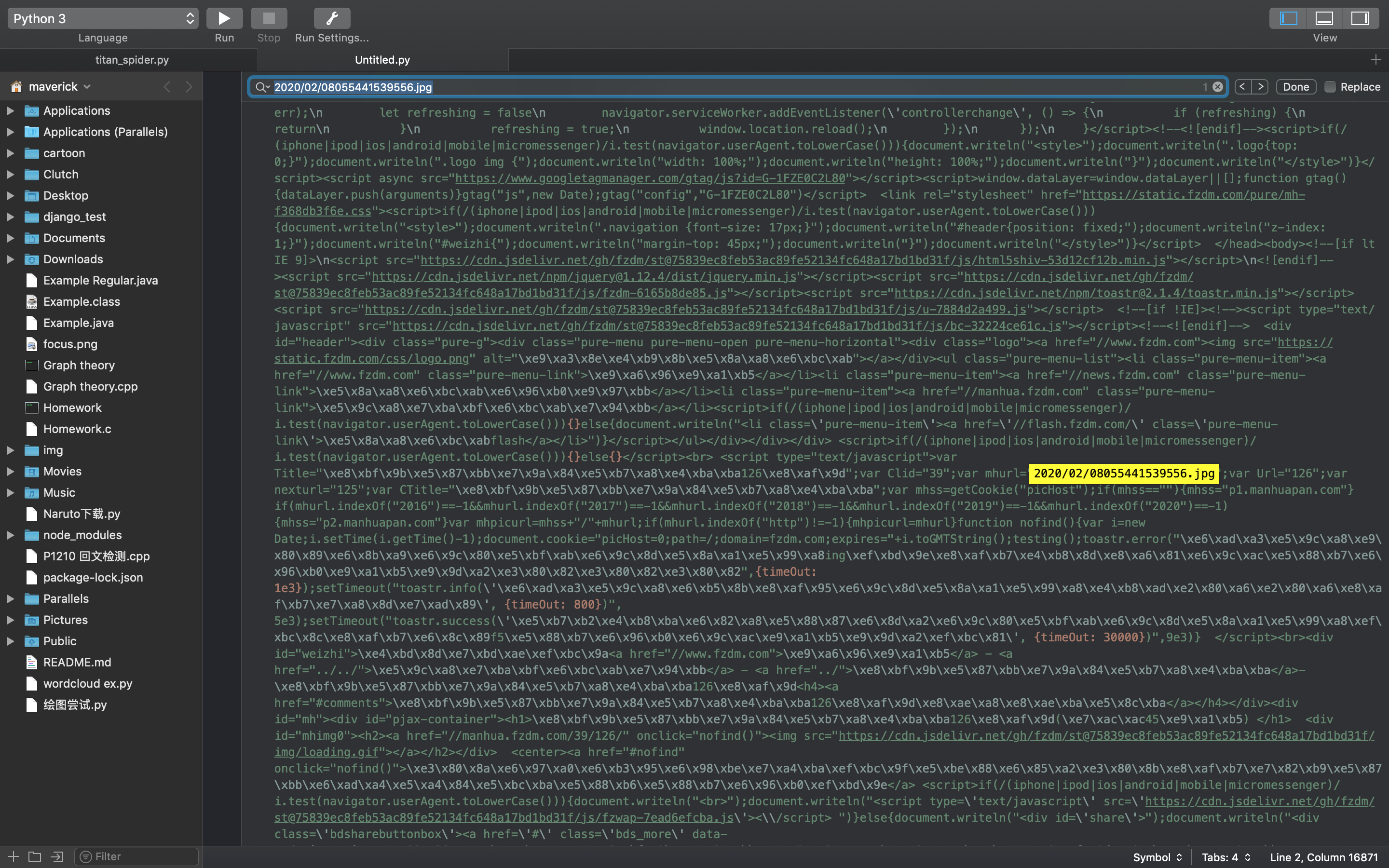
我们发现这个url放在javascript里面,使用document.write()。。。
你以为我有什么骚操作???

我还真没有。。。
找到script
1 | |
于是我们获得了一个很大的array which有我们需要的url
博主是个铁憨憨,强行用python的正则表达式找到了这个url
正则表达式不会的可以走这里
在编程的时候,我们就先记录下这些script,然后再继续操作
1 | |
五、开始编写
还记得我们最开始的parse()吗?我们现在给他添加一点东西
解释都在代码里面
1 | |
接下来我们编写comics_parse(self, response)函数来处理各话的url
1 | |
然后我们就可以欣赏它爬取的漫画了。因为整个网站的机制是一样的,所以我们只需要修改url地址,就可以任意爬取自己想看的漫画了。
五、后记
如果是自己想用的话,代码已经在GitHub上面了,下载下来就可以直接用。
不仅是巨人,这个爬虫还可以爬取整个网站上的其他漫画,比如:
一拳超人,火影忍者,海贼王,鬼灭之刃等。
请求星星✨
使用terminalcd到根目录然后运行以下代码:
1 | |
记得把保存的本机地址还有想爬取的漫画地址改一下
当然只要编程的速度够快,这种下载速度绝对比某网盘快得多,最关键的是方便并且可以装B。。。
放上自己爬到的兵长帅照哈哈哈哈哈

六、参考链接及版权说明
博主是第一次写博客,如果侵权请联系我删除,还有对两个大佬写的博客表示诚挚感谢,链接第一与第二个为两个大佬的博客。
参考链接:
1(合法).https://blog.csdn.net/c406495762/article/details/72858983
2(非法).https://moshuqi.github.io/2016/09/27/Python%E7%88%AC%E8%99%AB-Scrapy%E6%A1%86%E6%9E%B6/
3(正则表达式).https://www.runoob.com/python/python-reg-expressions.html
4(xpath与css学习).https://www.jianshu.com/p/489c5d21cdc7
5(下载图片方法).https://morvanzhou.github.io/tutorials/data-manipulation/scraping/3-02-download/
6(进击的巨人在线观看).https://manhua.fzdm.com/39/